Linkedin architecture which enables searching a message within 150ms
You get a message on LinkedIn from an old colleague asking for a referral. You’re busy, so you just quickly acknowledge the message but forget to save the resume they sent. A few days later, you remember the conversation but you feel lazy to scroll so you just type in keyword. The message is right there.

This simple action is exactly what LinkedIn’s messaging search system is all about. But what makes it so smooth? How does it work behind the scenes? Today, we’re going to dive into the architecture that powers LinkedIn’s search and the clever decisions that make it so fast and user-friendly. They crazy part is all this is done in 150ms.
Search Service
One core idea for searching the message is that each message search is confined to the user which means user can only search in their inbox. This is important as we know that for searching we only need to search for a user, we can create index for search based on the user.
However one key observation that Linkedin had was that not all users use the search functionality. So instead of creating and updating the index for every user they only create index for the users who actively do the search. This was done to optimize both the cost and the write performance, the reason if they store index for each user it would be stored in the disk as an in-memory index for each user will be costly. Storing the index in a disk in the write heavy system would mean reading the index from the disk, decrypting the message, updating the message and the index again, encrypting it and storing it again in the disk. This would makes writes very in-efficient.
RocksDB: Storing Messages
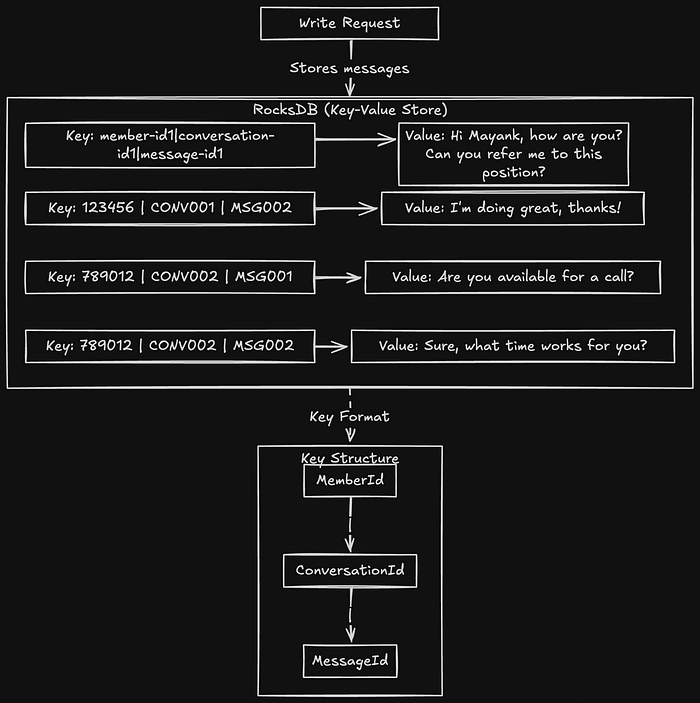
LinkedIn uses RocksDB, a high-performance key-value store, to store messages. The data structure for each message is simple, with a key-value pair representing the message metadata:
- Key:
MemberId | ConversationId | MessageId - Value: The content of the message, e.g.,
"Hi Mayank, how are you? Can you refer me to this position?"Please note that messages values are encrypted.
When a new message is received in a user’s inbox, it is stored in RocksDB as a new row with the member’s ID, conversation ID, and message ID. For example:
member-id1|conversation-id1|message-id1
Inverted Indexing with Lucene
Now, in order to search the messages, LinkedIn uses lucene which uses an inverted index — essentially a mapping of words (or tokens) to their occurrences across the documents (messages). Each message is treated as a document. For example:
Document 1:
{
"message": "Hi Mayank, how are you? Can you refer me to this position?"
}
Document 2:
{
"message": "Hi Mayank, can you refer me to this new position?"
}
Step 1: Tokenize the Messages
The messages are tokenized into individual words (ignoring punctuation and making everything lowercase):
Document 1 Tokens:
["hi", "mayank", "how", "are", "you", "can", "you", "refer", "me", "to", "this", "position"]
Document 2 Tokens:
["hi", "mayank", "can", "you", "refer", "me", "to", "this", "new", "position"]
Step 2: Build the Inverted Index
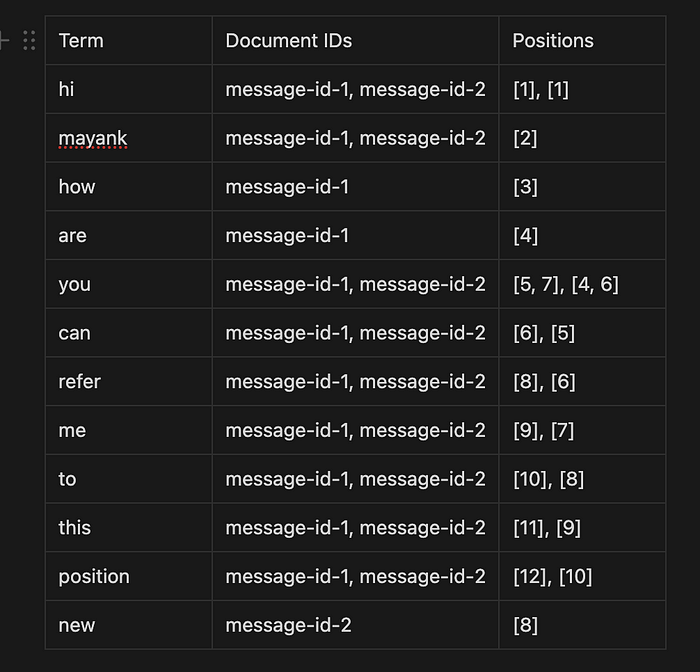
Lucene creates an inverted index by mapping each word (token) to the documents where they appear. Here’s how it would look for both documents:
Explanation of the Inverted Index:
- “hi” appears in both documents (
message-id-1andmessage-id-2). It is located at position 1 in both messages. - “you” appears in both documents at different positions: in
message-id-1at positions 5 and 7, and inmessage-id-2at positions 4 and 6. - “refer” appears in both documents at position 8 in
message-id-1and position 6 inmessage-id-2.
Step 3: Perform a Search
When a user searches for the word “refer”, the system will:
- Look up “refer” in the inverted index.
- Find that it appears in both
message-id-1andmessage-id-2at positions 8 and 6, respectively. - The system can then quickly retrieve the relevant messages from both documents.
An important performance optimization LinkedIn implemented is that the index is stored in memory rather than on disk. This is critical for performance, as storing the index in memory allows for faster search results, minimizing latency. When a search request is made, the system quickly scans through the in-memory index and returns the results.
How do they decide when to create index?
LinkedIn doesn’t create indexes for all users automatically. Instead, it triggers index creation when a search request is made. Here’s how it works:
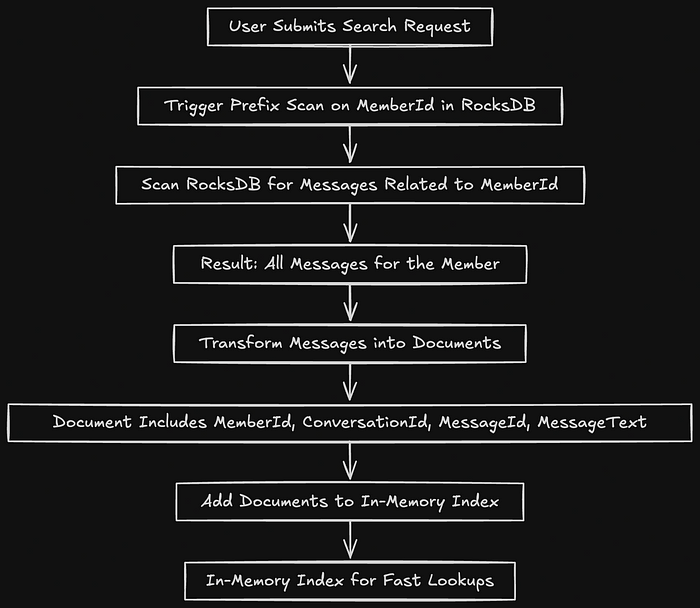
- Search Request: When a user submits a search request, the system runs a prefix scan on the
MemberIdin RocksDB. This retrieves all messages related to that user. - Document Creation: For each message, a document is created that contains the member ID, conversation ID, message ID, and the message text.
- Index Construction: The document is added to an index, which is stored in memory for fast lookups.
Partitioning
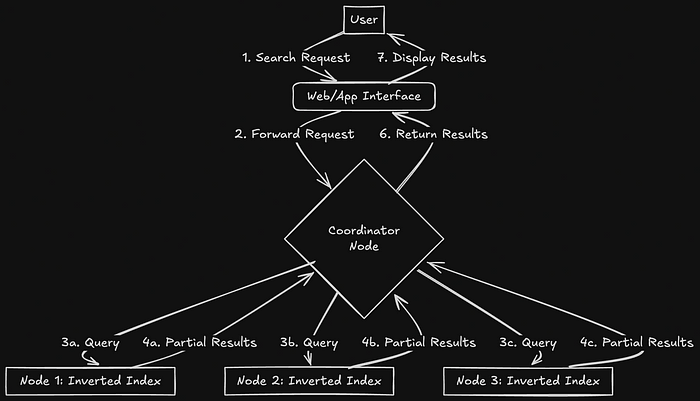
The indexes are partitioned across multiple nodes in the system, and the partitioning is done based on MemberId and DocumentId. This ensures that no single node becomes overwhelmed by a high volume of messages from one particular user.
To achieve this, there is a coordinator node that acts as the entry point for all search queries. The coordinator node sends the search query to various nodes, collects the results, and ranks them based on relevance before sending the final results back to the user.
Using Zookeeper for Node Coordination
LinkedIn relies on the internal service D2, a distributed coordination service, to maintain information about the nodes in the system. D2 helps the coordinator node determine which nodes should handle the search request, ensuring the query is sent to the correct nodes.
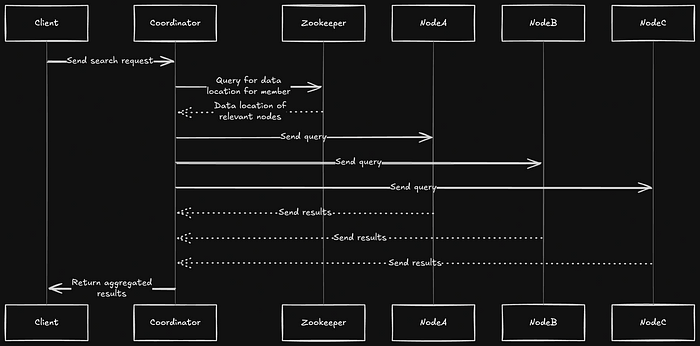
Furthermore, LinkedIn employs sticky routing, which means that all search requests for a given member are routed to the same replica. This ensures consistency in search results and prevents the index from being rebuilt on multiple replicas, thus improving performance and consistency.
Conclusion:
We looked at some of the cleaver design decisions that Linkedin made which not only helped them save time on search but also helped them reducing the cost of infrastructure. They implemented their in house search solution which caters to their needs.
References: